Matt Chapman

Data Scientist with 4+ years of commercial experience in analytics, strategy and sales and a master's degree in Data Science from Oxford University. Previously at Vodafone, VIMA Group (management consulting), Ovo Energy, HSBC.
Ranked in top 10% of undergraduate cohort at Cambridge University.
View my LinkedIn Profile
Selected projects in data science, machine learning and NLP
Deep NLP for hate speech detection
Hate speech detection is the automated task of determining whether a piece of text contains hateful content. In this project, I built a classifier using PyTorch to fine-tune a BERT model.
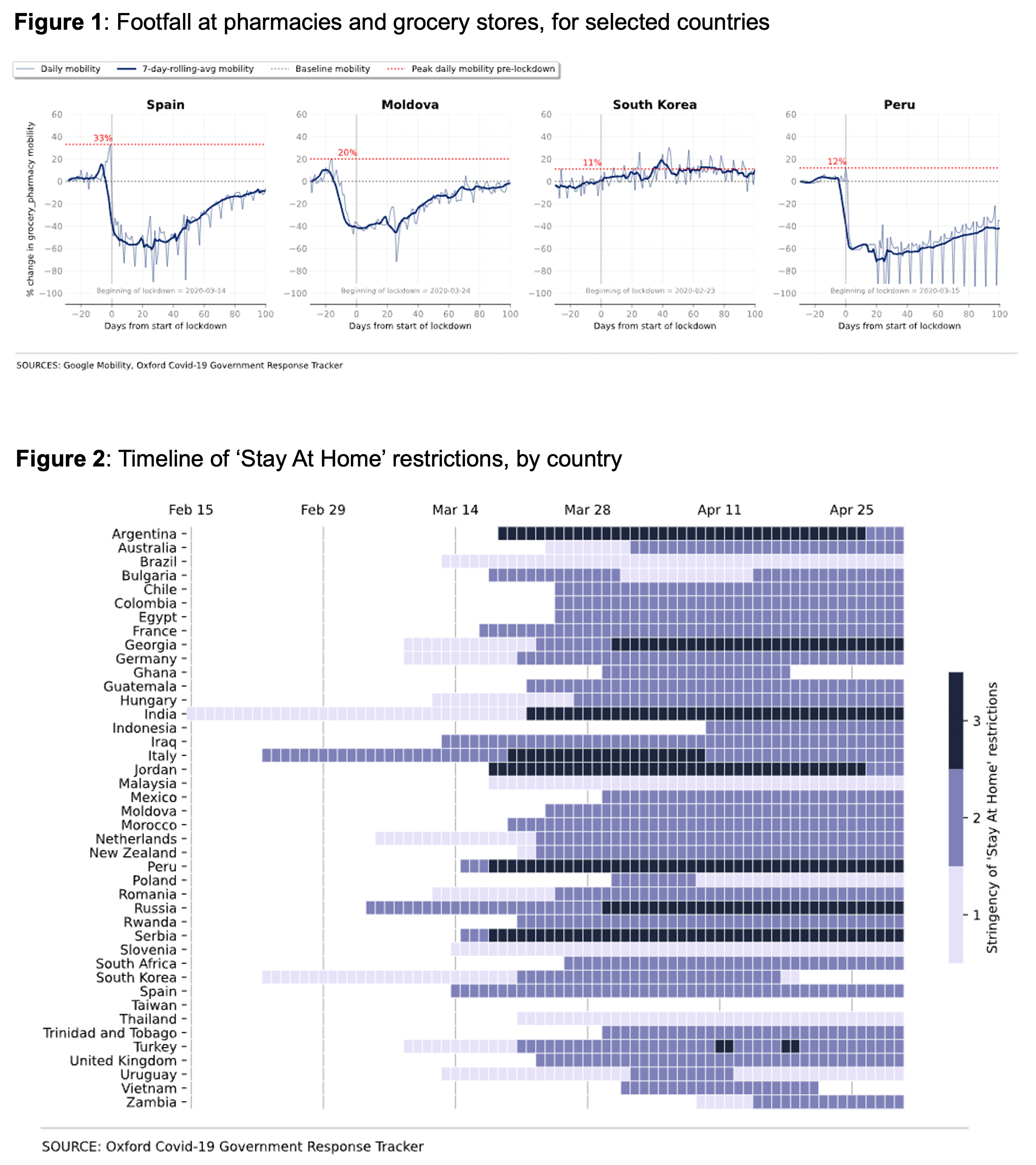
Examining panic-buying during the first wave of Covid-19, using mobility data
The first wave of COVID-19 infections led to widespread stories of shortages in grocery stores as consumers stocked up in anticipation of lockdowns, a behaviour colloquially known as ‘panic buying’. In this project, I used mobility data from Google and Apple to empirically investigate the extent of panic buying in different countries.
View code on Colab
The Fragile Families Challenge: ML with Bayesian hyperparameter tuning, KNN missing values imputation, and data preprocessing Pipelines
The Fragile Families Challenge was a predictive modelling challenge commissioned by researchers at Princeton University in 2017. In the challenge, participants were tasked with predicting six life outcomes (GPA, material hardship, grit, eviction, layoff, and job training) for 4,242 children based on their cirumstances between birth and age 9.
I took part in this challenge, using various ML and NLP techniques including: (i) imputing missing values using word embeddings and KNN, (ii) modelling with LASSO, Random Forests and XGBoost models, (iii) Bayesian hyperparameter optimisation, and (iv) using feature importance scores to interpret the models’ predictions.
Implementing a custom data collection pipeline using Scrapy and MongoDB
The web hosts vast quantities of data useful for research. In this project, I built a custom data collection pipeline using the Python library scrapy and a MongoDB cluster.
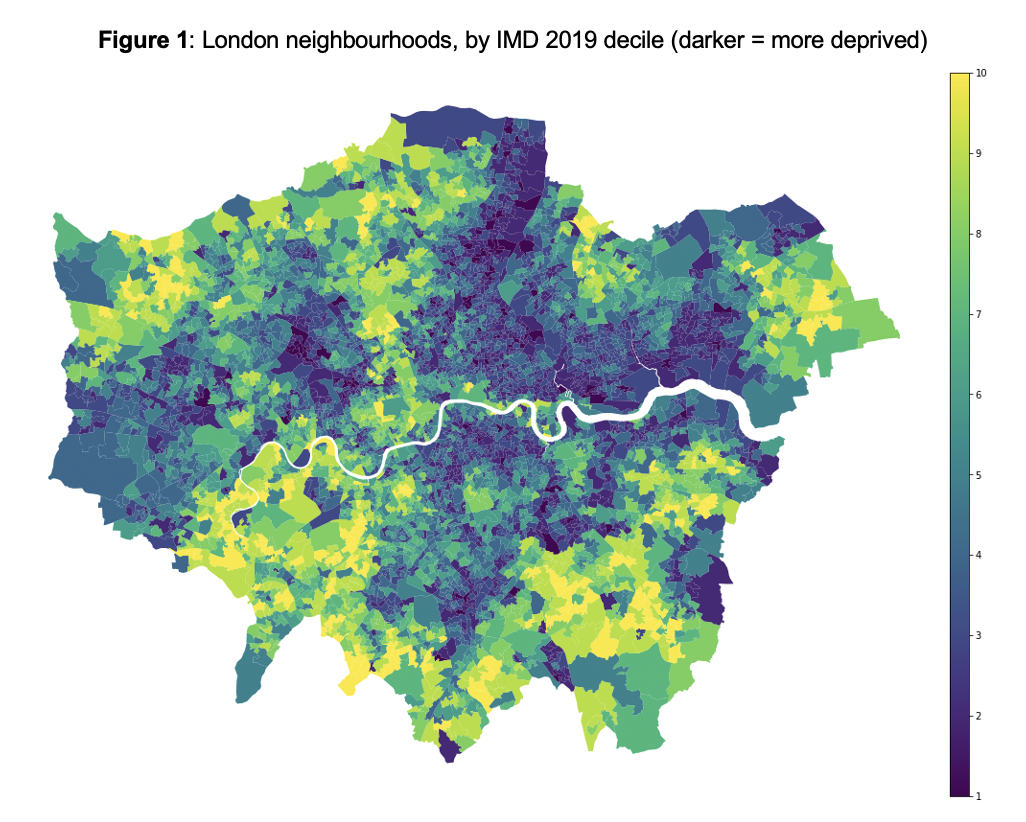
Geospatial analysis of deprivation in London
In this project, I use Geopandas to visualise data on deprivation levels in London and analyse changes over time.
View code on Colab
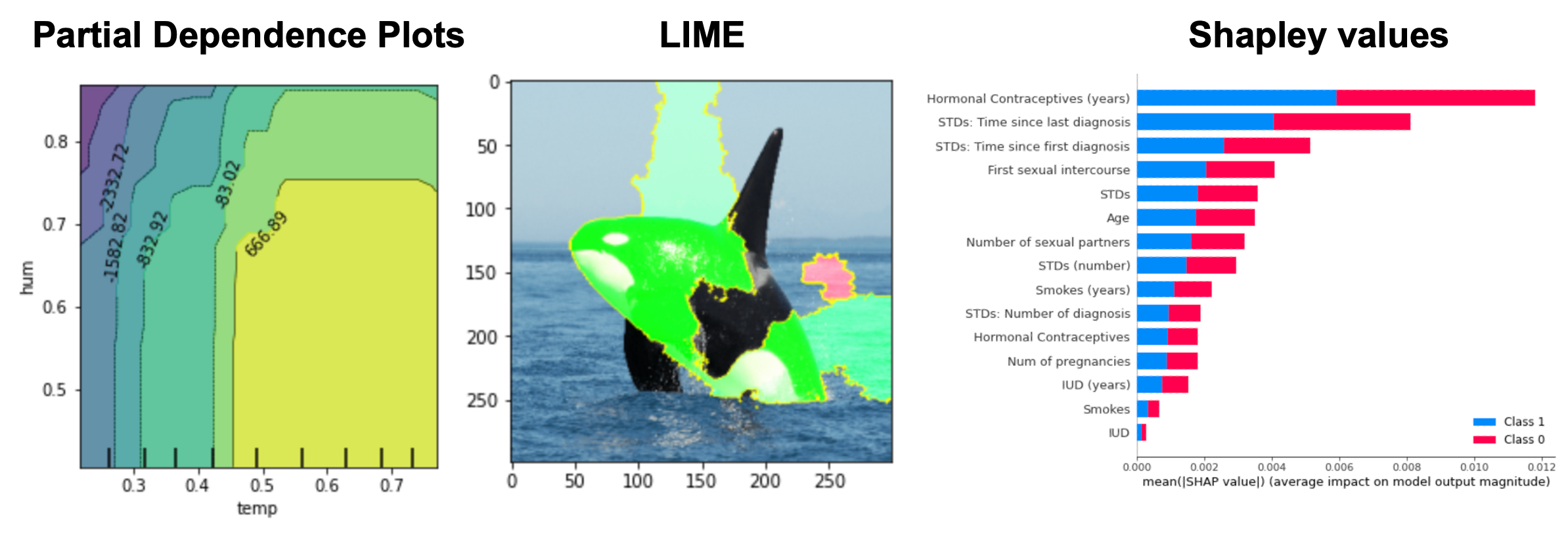
Interpretable machine learning: Parital Dependence Plots, LIME and Shapley values
A significant barrier to ML’s adoption in many fields is the lack of interpretability of black box models. In this project, I use several techniques to gain insights into various models.
Using multi-level modelling in R to investigate the drivers of Covid-19 vaccine hesitancy
In many tasks, failing to account for the hierarchical relations and autocorrelations between data can create “ecological fallacies” which misguide our interpretation of the data. In this project, I use mutli-level regression modelling to account for spatial autocorrelation and study reasons for Covid-19 vaccine hesitancy.
View code on Github
Skills-based projects
A selection of smaller projects demonstrating specific data science and ML skills.